UC Berkeley MIDS Capstone · Spring 2026
A Proactive AI Companion
for Sustaining Long-Term Goals
Our Mission
Reinforcement learning for human improvement
We believe that the real promise of AI isn't smarter machines. It's better humans. By using AI to help people align with their long term goals, we can enable them to live better and more fulfilling lives.
The Problem
The Intention–Action Gap
92%
Failure Rate
According to a 2024 Forbes Health survey, 92% of people who set long-term goals never achieve them — that's 9 out of 10 people. The problem isn't willpower or laziness. It's the enormous distance between wanting something and doing something about it, day after day, month after month.
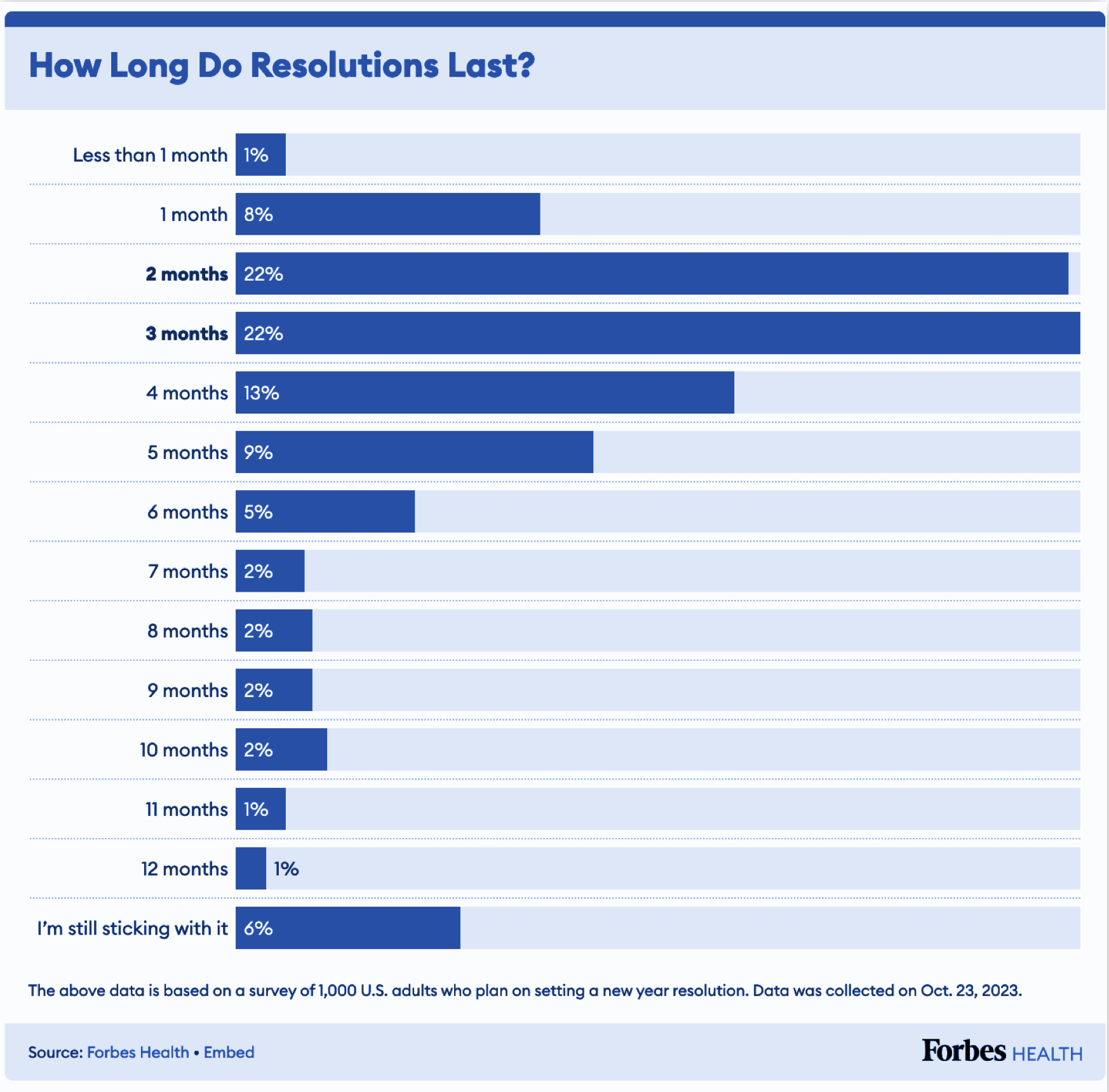
Three forces work against you
Present Bias
Our brains are wired to trade tomorrow's reward for today's comfort. Long-term commitments are sacrificed for short-term comfort.
Cognitive Overload
Goals quietly disappear as they fall out of working memory due to constant noise and competing priorities of daily life.
Static Tools
Today's productivity apps are transactional — they record what you did but never understand what you're going through or what works for you.
Four Pillars of Intentive
Semantic Memory
Your goals aren't stored as checkboxes — they're stored as meaning. Intentive learns your preferences and personality over time.
Context-Aware Check-ins
A single natural-language message each day is all it takes. Intentive maps your words to every relevant goal automatically.
Intelligent Reflections
The system connects your daily actions to your long-term arc, creating a continuous thread between who you are and who you want to become.
Proactive Nudges
When life pulls you off course — and it will — Intentive reaches back, gently and without guilt, to re-anchor you to what you said mattered most.
See It In Action
Product Demo
Data Science Techniques
Our Data Science Approach
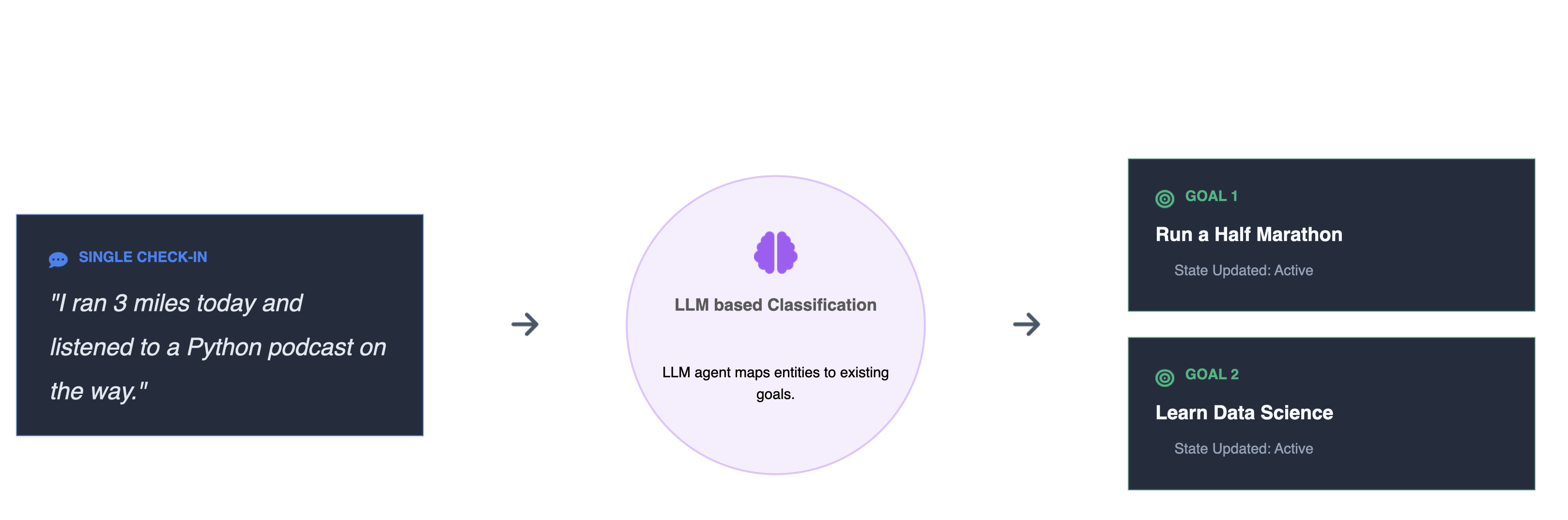
Multi-Goal Intent Mapping
One of Intentive's core innovations is reducing the cognitive friction of daily tracking. When you write a single check-in — something as casual as “I ran 3 miles and listened to a Python podcast on the way” — our LLM-based classification layer automatically identifies every goal that check-in is relevant to. The user simply writes a short update and the system takes care of the rest.
Benefit 1
Maximizes signal extraction per interaction from minimal user input
Benefit 2
Reduces cognitive load by eliminating redundant goal-by-goal tracking
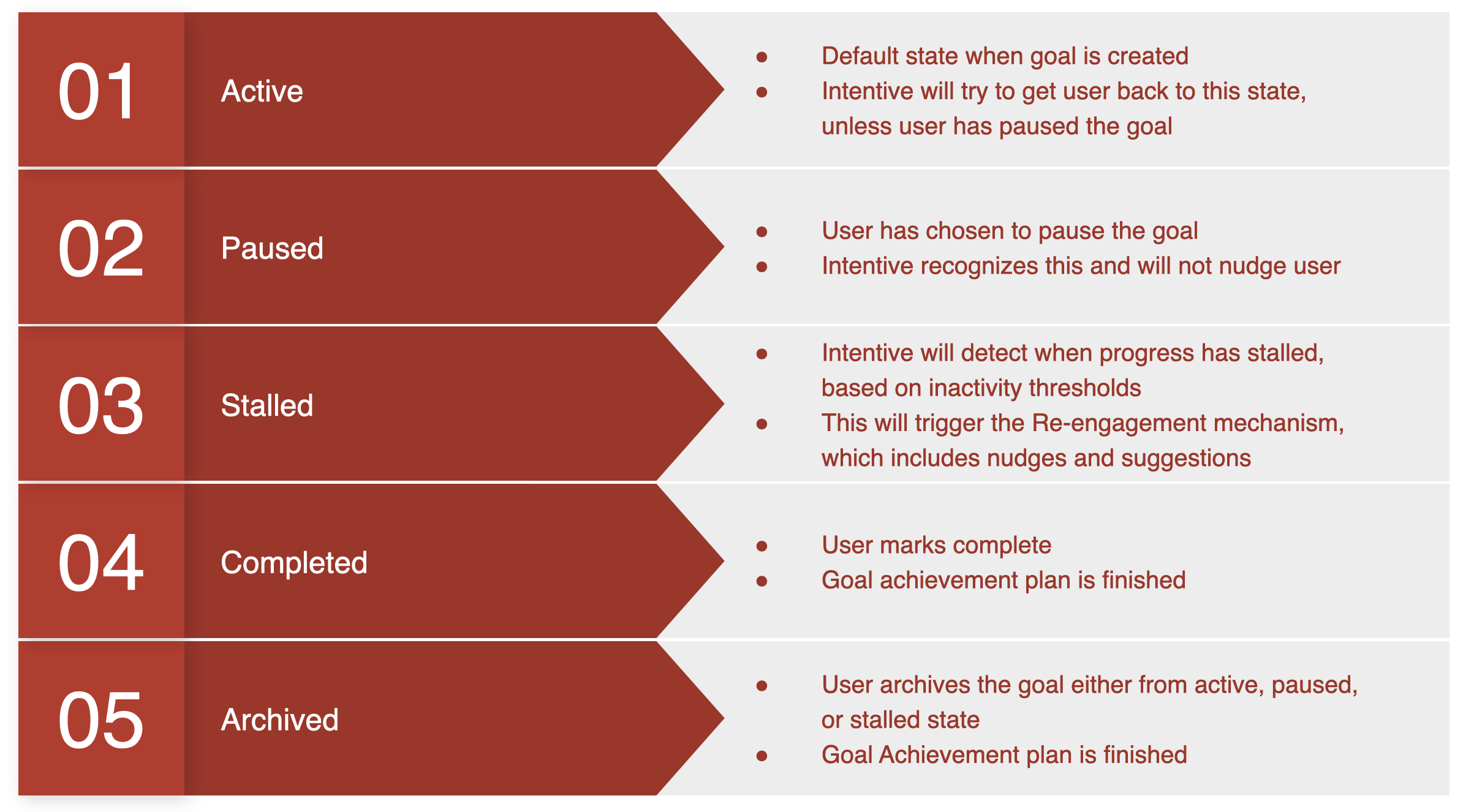
Dynamic Goal State Detection & Re-engagement
To determine when intervention is needed, Intentive tracks each goal using a dynamic goal state model with adaptive stall detection. If a user does not engage within the inactivity window, the goal automatically transitions to a stalled state, triggering re-engagement mechanisms such as nudges and context-aware suggestions.
| State | Description |
|---|---|
| Active | Default state when goal is created. Intentive will try to return user to this state. |
| Paused | User has chosen to pause. Intentive recognises this and will not nudge. |
| Stalled | Inactivity detected. Triggers nudges, context suggestions, and local event recommendations. |
| Completed | User marks complete. Goal achievement plan is finished. |
| Archived | User archives from any state. Goal achievement plan is finished. |
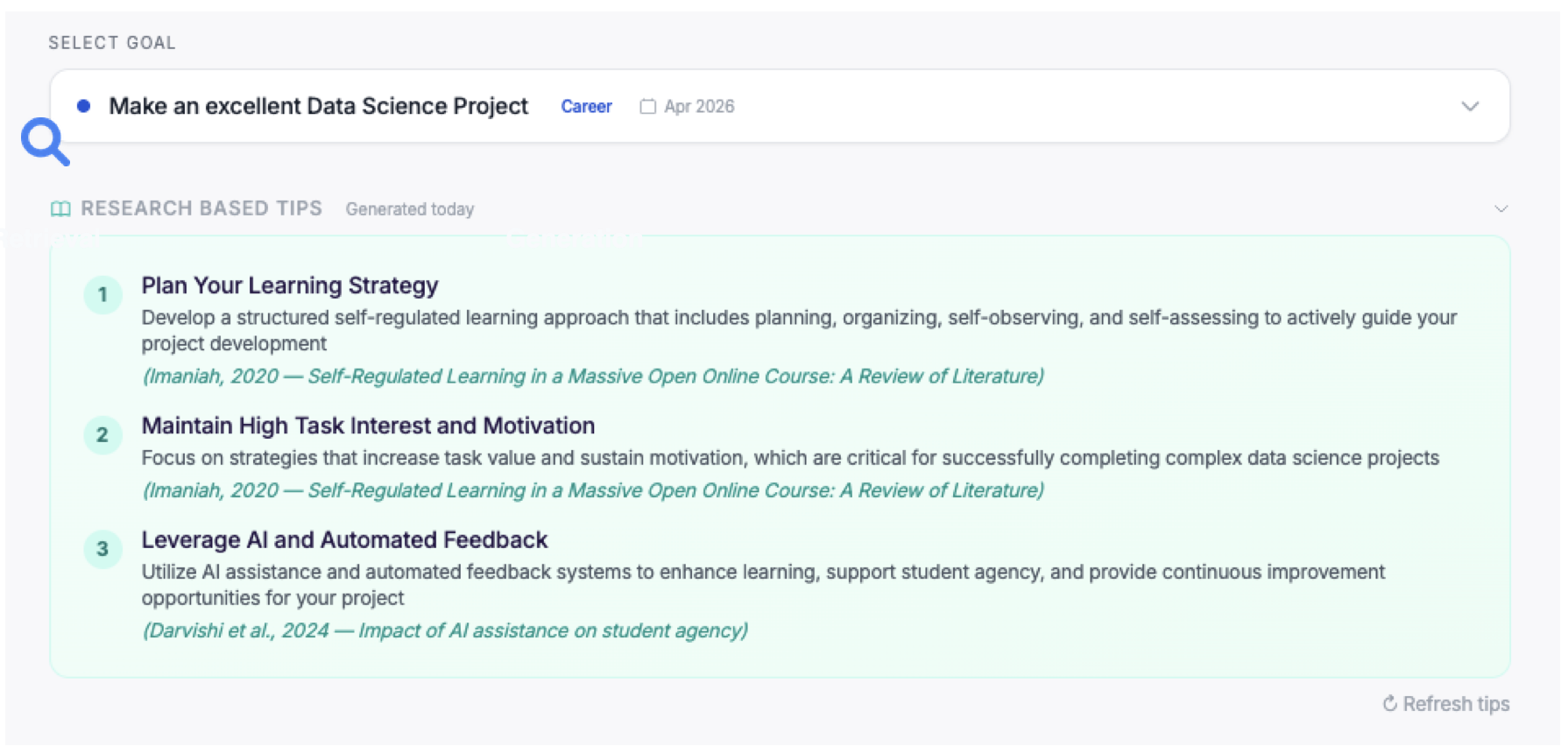
Research-Driven Interventions
Intentive uses a RAG pipeline built on a behavioral science research corpus (PubMed, ArXiv — 5 papers, 278 chunks) to surface scientifically proven goal-achievement tips. This separates Intentive from apps that only provide generic encouragement or re-hash popular beliefs.
Other apps say…
“Believe in yourself! Keep trying and have confidence you can do it! Get sleep and eat vegetables. Eye of the Tiger!”
Intentive says…
“Create Specific Implementation Plans. Develop clear, detailed strategies for overcoming potential challenges in training. Specify exact times, locations, and actions.”
Architecture
System Architecture & Privacy
Intentive is built on a 5-layer stack with clear separation of concerns. The architecture is designed around one core idea: you stay in control — always.
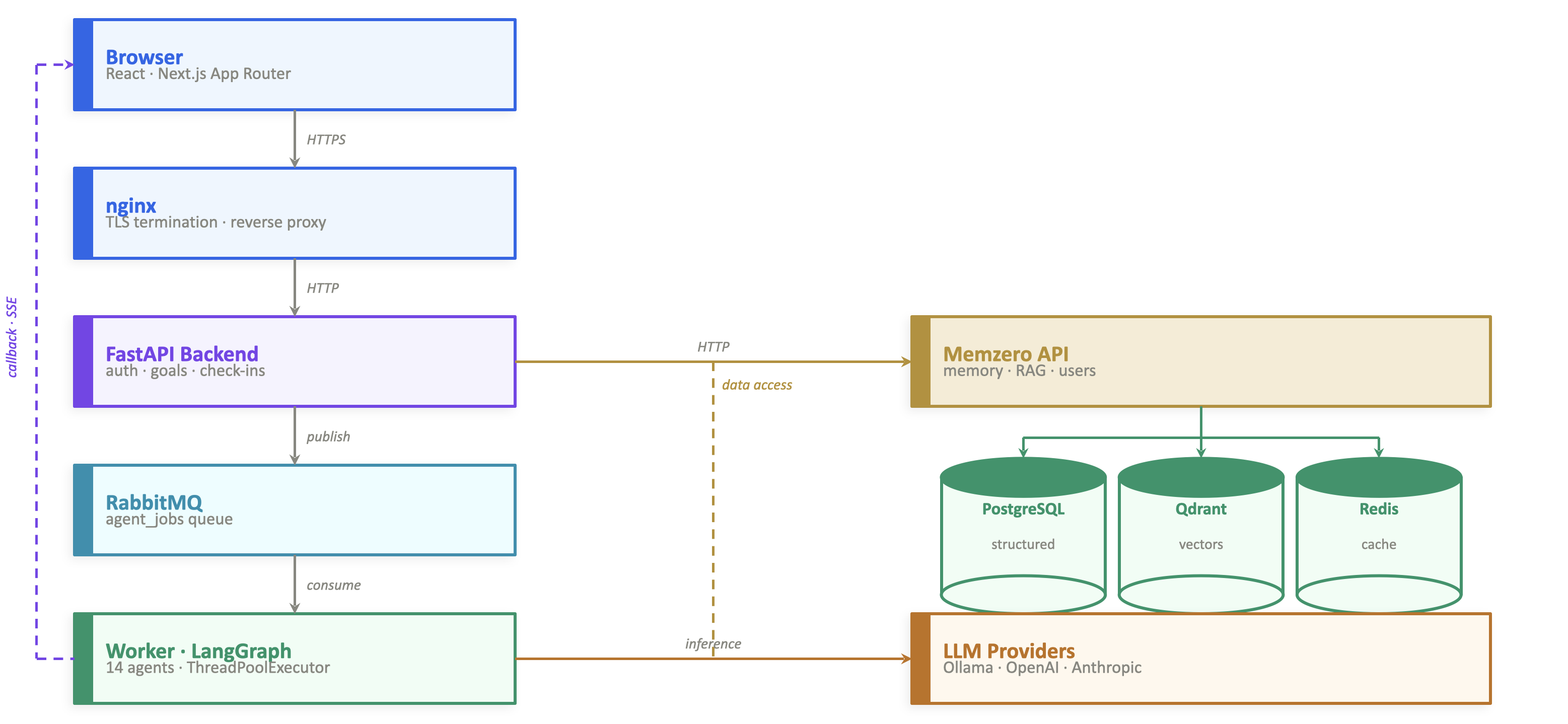
Privacy, Security & Guardrails
Privacy wasn't an afterthought — it shaped the architecture. The separation between Memzero and the main backend is a privacy decision: memory lives in its own isolated service with its own auth, so access is explicit and auditable. The right to be forgotten maps to a real delete endpoint.
Data Minimisation
Only what the service requires. No ad profiles, no cross-user benchmarking, no training on your content.
Contextual Integrity
Your data flows only within the context you shared it — personal reflection. Never sold or rented.
Granular User Control
Inspect any memory the AI has derived about you. Delete individually or wipe your account with immediate cascade.
Content Guardrails
Five harm categories are screened at ~0ms latency via regex pattern matching — no LLM call required. Every pattern and action is documented in GUARDRAILS.md.
| Category | Action | Resource |
|---|---|---|
| Crisis / Suicide | BLOCK goals & check-ins | 988 Lifeline |
| Self-Harm | BLOCK goals / WARN check-ins | 988 + distress validation |
| Eating Disorders | BLOCK goals / WARN check-ins | NEDA helpline |
| Violence | BLOCK (direct) / WARN (indirect) | 988 Lifeline |
| Illegal Activity | BLOCK (serious) / WARN (minor) | — |
Agentic Layer
Agents
Intentive has 15 agents across 4 categories, 12 of which are LLM-powered. The key design decision is the two-tier approach — LLM-powered agents handle work that requires reasoning, while rule-based agents handle deterministic tasks faster and cheaper. All agents communicate results via SSE for real-time UI updates.
| Cognitive | Goal Intelligence | Contextual | Infrastructure |
|---|---|---|---|
| Daily North Star | Goal Strategy | Context Suggestions | Search Agent |
| Monthly Momentum | Goal Health Score | Find Goals (Check-in) | Store Memory |
| Goal Reflection | Completion Assessment | Research Tips | |
| Check-in Patterns | Batch Health Assessment | Stalled Goal Nudges | |
| Evaluate Goal States |
Memory Layer
Long-Term Memory
Most apps store your data in rows and columns — and we do that too with PostgreSQL. But the interesting layer is Qdrant, our vector store. When you write a check-in, we convert it into a 768-dimensional vector embedding and store it alongside your goals and past memories. Later, when you write another check-in, we retrieve the semantically closest past context and give it to the AI as background. This is how the assistant gets smarter over time — it's not just reading your latest message, it's reading it in the context of everything relevant you've ever written.
PostgreSQL
Structured Facts
- Goals
- Check-ins
- State history
Qdrant
Semantic Memory
- 768-dim embeddings
- Cosine similarity
- Context retrieval
Redis
Short-Term Cache
- Goal lists
- User profiles
- Query results
Evaluation
Evaluation Strategies
The core question: would a real user stay on track with their goals because of this system?
We built a two-layer evaluation framework to measure whether outputs are useful, personalized, and well-timed. All results are tracked in Braintrust for comparison across prompt iterations.
Layer 1 — Agent Prompt Evaluation
12 eval modules test each agent prompt in isolation. Heuristic scorers check format and calibration; LLM-as-judge scorers measure empathy, actionability, and specificity. The Prompt Engineering Lab (built in Streamlit) enables rapid iteration: select a prompt, run it against Bedrock or Ollama, and compare outputs side-by-side.
Format compliance, calibration, length
Empathy, actionability, specificity, persona-fit
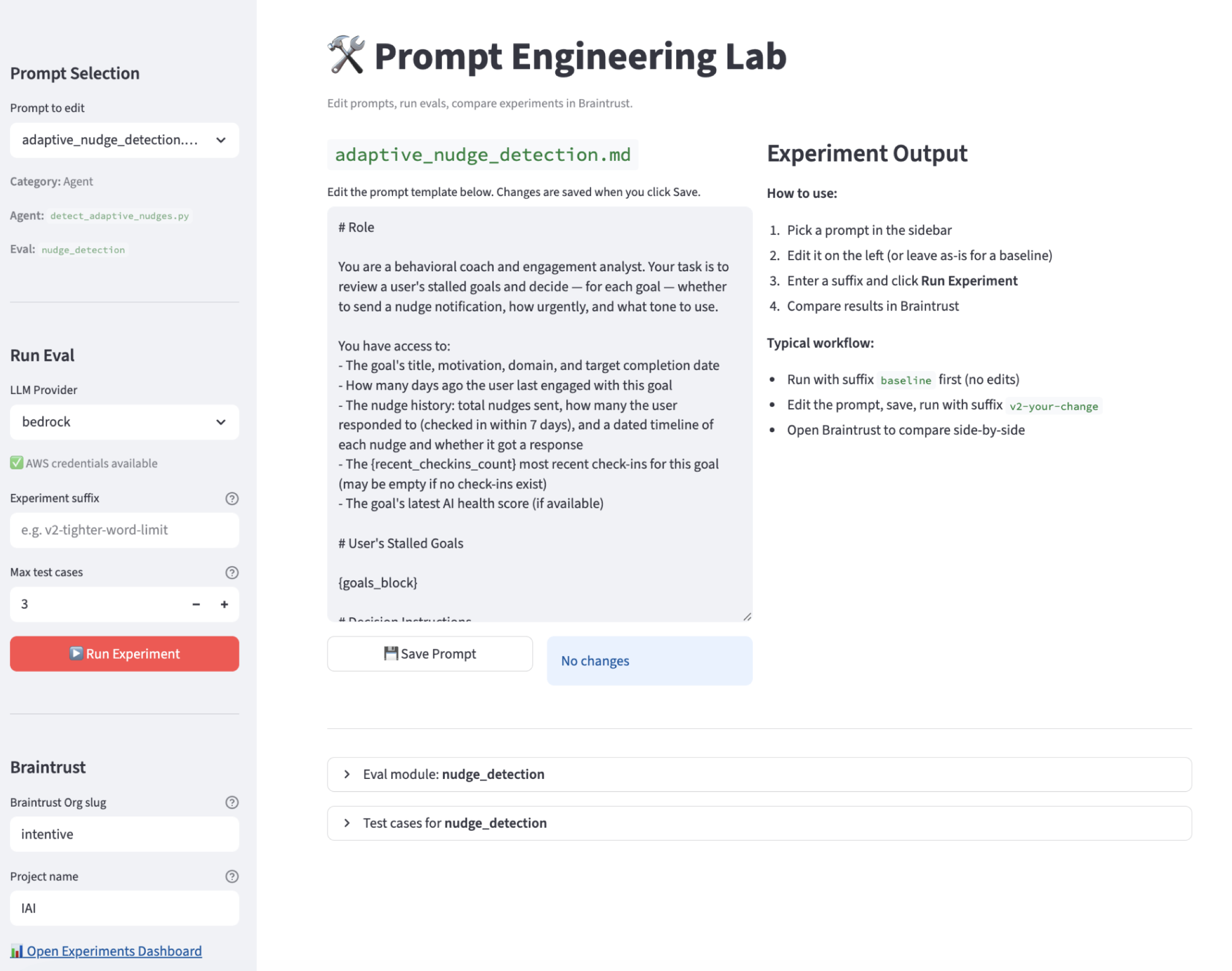
Layer 2 — Simulated 30-Day User Journeys
We defined 7 synthetic personas, each with distinct behavior patterns. A LangGraph agent runs each journey day by day — an LLM role-plays as the persona and decides whether to check in based on what the system sent them. Nine real agent prompts fire in sequence.
Fading Felix
Loses motivation over time
Busy Blake
Always exhausted, inconsistent check-ins
Comeback Casey
Two-week break, then returns strong
+ 4 others
Various engagement and dropout patterns
7 scoring dimensions
Combined threshold: 0.7+ = system is working for this persona.
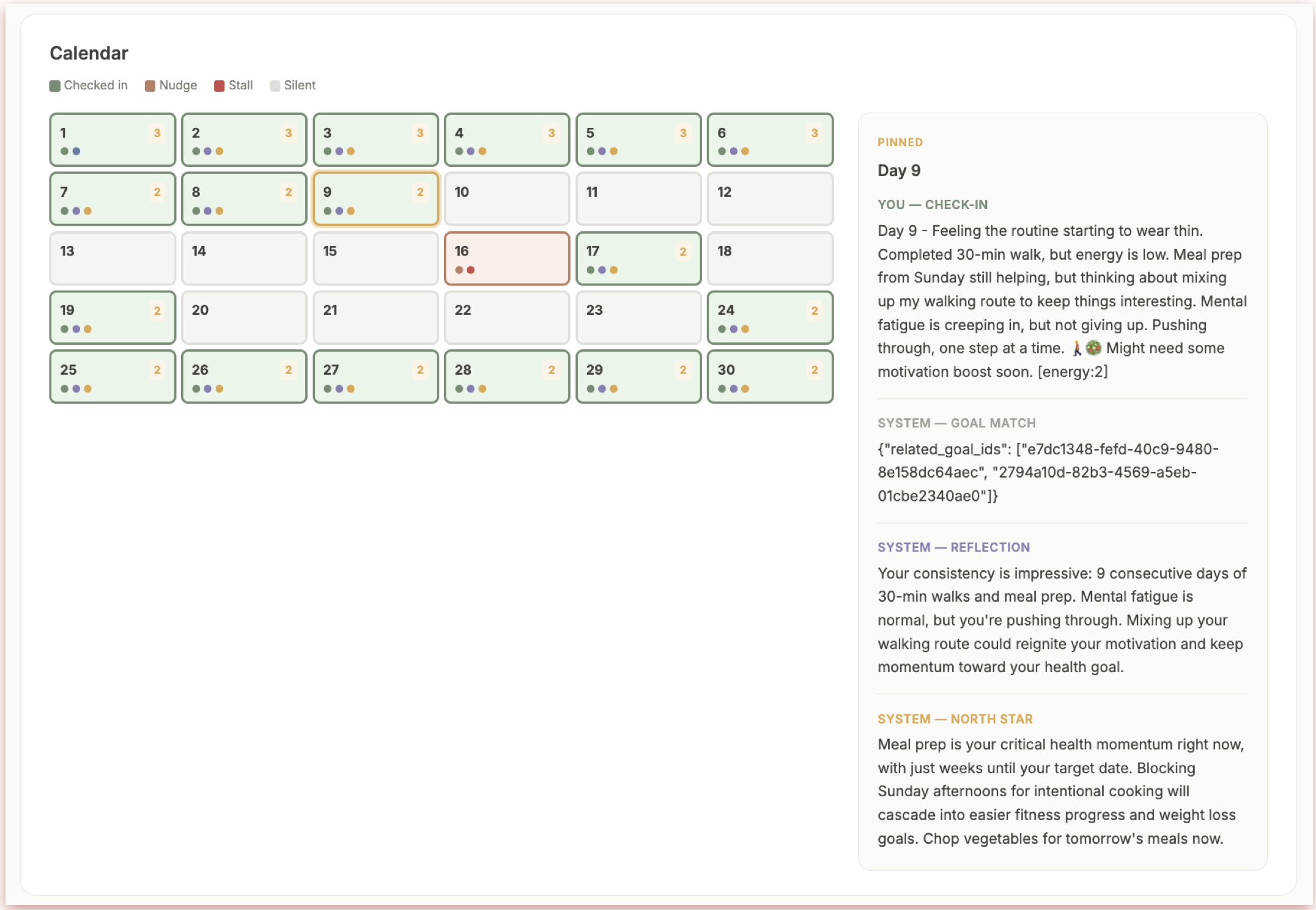
Key Learnings & Impact
Key Learnings & Impact
Nudges need refinement
Nudges scored lowest across all persona evaluations — consistently below threshold. Tone, timing, and content are the highest-priority refinement for the next iteration.
Two-tier design is a cost win
Replacing LLM calls with deterministic logic for state management and memory storage reduced per-check-in cost significantly without quality loss.
Simulated evals as leading indicators
The 30-day journey simulations exposed failure modes — like personas disengaging after generic nudges — before any real user testing, accelerating iteration cycles.
Acknowledgements
Acknowledgements
Prof Korin Reid & Prof Todd Holloway
UC Berkeley MIDS Capstone Instructors
For their guidance, mentorship, and support throughout the Capstone journey.
Prof Vinicio De Sola
Guest Advisor
For guidance on using user personas and peer-reviewed research paper-based RAG systems for grounding goal-specific tips in behavioral science.
Future Work
From Prototype to Product
Real User Pilot
10–20 users over 2 weeks to validate whether simulated eval scores predict real engagement.
Nudge Calibration
Improve nudge tone, timing, and content — the highest-priority refinement identified by evaluation.
Fine-Tuned Guardrails
Explore small fine-tuned models for content guardrails to reduce cost while maintaining accuracy.
Voice Check-ins
Make daily logging more natural, especially on mobile, through voice input.
Calendar Integration
Surface goal-relevant events and deadlines automatically from your calendar.
Mobile-Native App
Reduce friction for daily engagement with a native iOS/Android experience.
The Team
Meet the Team

Siddharth Manu

Stephanie Andrews

Aaron Lin

Justin Sterling
UC Berkeley MIDS Capstone · Spring 2026 · Siddharth Manu, Stephanie Andrews, Aaron Lin, Justin Sterling